8.7 KiB
ECE 222: Digital Computers
Exceptions
In ARM, anything that interrupts the normal control flow of a program is an exception.
- An interrupt from an interrupt request (IRQ) occurs when a peripheral wants to interrupt the current flow
- A fault indicates a CPU error (e.g., division by zero) and returns to the faulty instruction
- A trap runs the interrupt handler and returns to the next instruction
Exceptions are handled by running an exception handler then returning to the original line.
Vector table
A vector table is an array of handler addresses. Each index contains a number (a “vector”) and a priority.
Exception handling
First, in hardware: If the exception priority is higher than the current operating priority, the exception is immediately handled.
- the current context is pushed to the stack
- the operating mode is set to privileged
- the operating priority is set to the exception priority
- the program counter is set to the address of the exception
(
vector_table[exception_num])
Next, the handler runs, and it should:
- preserve the any R4-R11 it modifies
- clear the interrupt request (IRQ)
- restore R4-R11
- return with
BX LR
Finally, in hardware:
- the previous context is restored
- the previous operating priority and mode are restored
!!! warning Interrupts can interrupt other interrupts, if their priority is sufficiently high!
!!! example How to interrupt-driven I/O:
**Write the ISR:** Assuming that the IRQ bit is cleared if `R0` is read:
```asm
ISR PUSH {R4-R11} ; save previous state onto stack
LDR R3, [R0] ; clear the IRQ by reading from it
POP {R4-R11} ; restore state
BX LR ; return to original address
```
**Store the interrupt handler in the vector table:** Assuming that the vector number is `22` and the vector table starts 16 addresses after the 0x00:
```asm
MOV32 R0, #ISR ; handler address
MOV R1, #38 * 4 ; offset: (16 + 22) * 4 bytes per address
STR R1, [R0] ; save address to table
```
**Enable interrupt requests:**
```asm
MOV32 R0, #ADDRESS_INTERRUPT_ENABLE
MOV R1, #1
STR R1, [R0] ; enable interrupts
```Processor design
Comparing the complex instruction set computer architecture to the reduced instruction set computer architecture:
| Task | CISC | RISC |
|---|---|---|
| ALU operands can come from? | registers, memory | registers (load/store) |
| Addressing mode | complex | simple |
| Binary size | small | large (~30% larger) |
| Instruction size | variable | fixed |
| Pipelining | difficult | simple |
Operation encoding
The R-format is used for operations of the form
ADD Rd, Rn, Rm:
\[\underbrace{\text{op-code}}_\text{11 b}\ \ \overbrace{\text{Rm}}^\text{5 b}\ \ \underbrace{\text{shift amount}}_\text{6 b}\ \ \overbrace{\text{Rn}}^\text{5 b}\ \ \underbrace{\text{Rd}}_\text{5 b}\]
The D-format is used for operations of the form
LDR Rt, [Rn, #offset]:
\[\underbrace{\text{op-code}}_\text{11 b}\ \ \overbrace{\text{offset}}^\text{9 b}\ \ 00\ \ \overbrace{\text{Rn}}^\text{5 b}\ \ \underbrace{\text{Rt}}_\text{5 b}\]
The CB-format is used for operations of the form
CBZ Rt, LABEL:
\[\underbrace{\text{op-code}}_\text{8 b}\ \ \overbrace{\text{offset}}^\text{19 b}\ \ \underbrace{\text{Rt}}_\text{5 b}\]
Instruction data path
To execute an instruction, the following steps are observed:
- Instruction fetch (IF)
- fetch the instruction from instruction memory
- increment the instruction address (
PC += 4), latchedd into PC register at the end of the CPU cycle
- Instruction decode (ID)
- decode fields like the op-code, offset
- read recoded registers
- Execute (EX)
- ALU calculates ADD, SUB, etc, as well as addresses for LDR/STR, sets zero status for CBZ
- branch adder calculates any branch target addresses
- Memory (ME)
- if memory needs to be reached, either
WriteorReadmust be asserted to prepare for it - write to memory
- Writeback (WB)
- write results to registers from memory, the ALU, or another register
Performance
Each step in the instruction data path has a varying time, so the clock period must be at least as long as the slowest step.
Performance is usually compared by comparing the execution times of standard benchmarks, such that:
\[\text{time}=n_{instructions}\times\underbrace{\frac{\text{cycles}}{\text{instruction}}}_\text{CPI}\times\frac{\text{seconds}}{\text{cycle}}\]
Pipelining
Pipelining changes the granularity of a clock cycle to be per step, instead of per-instruction. This allows multiple instructions to be processed concurrently.
 (Source:
Wikimedia Commons)
(Source:
Wikimedia Commons)
Data forwarding
If data needs to be used from a prior operation, a pipeline stall would normally be required to remove the hazard and wait for the desired result (a read-after-write data hazard). However, a processor can mitigate this hazard by allowing the stalled instrution to read from the prior instruction’s result instead.
Load hazards
If a value is produced in memory access (e.g., loads) that is required in the next instruction’s EX. a stall is for the dependent instruction. This can be detected in the ID stage by testing if the current instruction sets the memory read flag and the next instruction accesses the destination register.
A processor stalls by disabling the PC and IF/ID write to prevent fetching the next instruction. Additionally, it sets the control in ID/EX to 0 to insert a no-op in the pipeline.
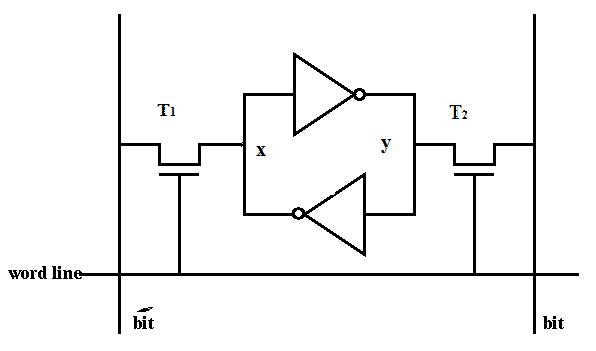
Memory
Static RAM (SRAM)
retains data as long as power is supplied
compared to DRAM, it is faster but more expensive, so it is used for cache
To read: set word line = 1, turning on transistors, then read the bit line’s voltage
To write: set word line = 1, turning on transistors, then drive the bit line’s voltage
Dynamic RAM (DRAM)
DRAM capacitors lose their charge over time so must be periodically refreshed
Roughly 5x slower than SRAM, but cheaper, so it is used for main memory
To read: precharge the bit line to \(V_{DD}/2\), then set word line = 1, then sense and amplify the voltage change on the bit line. This also writes back the value.
To write: along the bit line, drive \(V_DD\) to charge the capacitor (write a \(1\)) or \(GND\) to discharge (write a \(0\)).

Large DRAM chips
Each bit cell is placed into a symmetric 2D matrix to avoid linear searching. Assuming each addressing pin can address one byte (8 bits), including one bit to select row or column:
\[\text{\# addr bits} = \log_2(2\times\text{\# bytes})\]
The matrix would store a total of eight times the number of bytes / words, so each edge is the square root of that. To read an address, the memory controller gives the row on the address pins and asserts row address strobe (RAS). After the row is read, the controller gives the column and asserts column address strobe (CAS).
\[ \text{\# bits} = 2\times\text{\# bytes}\times\frac{\pu{8 bits}}{\pu{1 word}} \\ \text{matrix length}=\sqrt{\text{\# bits}} \]
!!! example A 16 Mib machine stores 2 MiB, or \(1024^2\) bytes. Thus the bits are arranged in a \(\sqrt{2\times1024^2\times8}=2^{12}\) by \(2^{12}\) matrix, where each row holds \(2^9\) 8-bit words.
DRAM timing
Asynchronous DRAM:
- Provide row number, assert RAS
- Wait
- Provide column number, assert CAS
- Wait
- Transfer data
Fast page mode DRAM:
- Provide row number
- Specify multiple column numbers
- Transfer multiple data
Synchronous DRAM (SDRAM) synchronises commands and data transfers to the bus clock. A row is buffered, then data is transferred in bursts of 2n words.
Double data rate SDRAM transfers data on the rising and falling edges of the bus clock.
DRAM performance
!!! definition - Latency is measured by the time from the start of the request to the start of data transfer. - Bandwidth is measured by the volume of data transferred per unit time
DDR SDRAM transfers 64 bits per channel at once. A rank of memory chips provides the data, and each rank chip is mounted on a dual inline memory module (DIMM). To increase capacity without increasing latency, each rank is subdivided into banks.
As a JEDEC standard, chips are named by DDR generation and bandwidth:
\[ \text{PC}\#-bandwidth \]
!!! example A PC3-12800 chip is DDR3 with a bus transfer rate of 12800 MB/s. Or, at 8 B/transfer, a bus clock rate of 1600 MT/s. At 2 transfers/cycle (DDR), it must thus run at 800 MHz.